
There are several link tracking and analysis tools used by marketers and SEOs to measure the success of their campaigns. Moz, Majestic, Ahrefs, and SEMRush are some of the more popular tools used to track inbound links to a website. All of these tools have different methods for crawling and indexing the web using their own software known as a web spider, a crawler, or a bot. Often times tracking inbound links is done for the research or reporting stages of a link building campaign making this data very important to proving impact to the c-suite, managers, or clients.
In this post I’ll be examining what data might be missing from different link tools and why that data is missing.
My interest in this started when I noticed links from Reddit were not appearing in my Majestic link reports. It turns out major websites around the web have blocked many crawler bots, including link analysis tools. To figure out who was blocked from crawling which website I used the top 100 list of USA websites on Similar Web, a list of top news websites from Feedspot, and a few websites not on either list I was curious about such as D Magazine for a total of 215 top websites. I then examined the robots.txt file on all of the websites from these lists and notated which link tool was likely blocked from which websites to help understand why links might be missing from a certain tool’s index.
TL;DR
Many SEO tool crawlers have been blocked in full or partially by major websites. Meaning if those websites linked to you, there’s a chance you’ll never know and you may need to use more than one tool provider or other methods to track links from these websites.
Key Findings
The most frequently blocked bot was [Ahrefsbot] by Ahrefs, which was blocked from crawling 8.8% of the 215 websites examined. Next up was Majestic’s [MJ12bot] which is unable to crawl 7.4% of the websites, [SEMRushbot] from SEMRush is blocked from 4.65% of websites, and Moz’s [rogerbot] is the least blocked being unable to crawl 4.18% of the 215 websites examined.
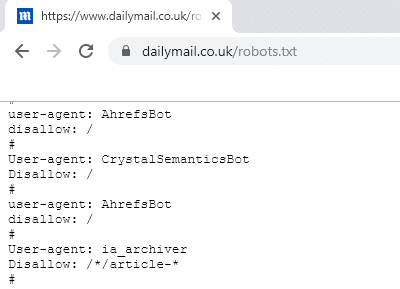
Ahrefs has been blocked specifically by publishing websites like the Daily Mail and Newsmax.com. Majestic has been blocked specifically from crawling large websites like Reddit and Wikipedia.
About the following information
Below I examine robots.txt files to see what websites these 4 link analysis tools are blocked from crawling:
- Ahrefs
- Majestic
- Moz
- SEMRush
Anything in brackets below [] is the user-agent of a website or service (i.e. the name of their bot as shown in server logs).
Bots were listed below as being blocked from crawling all content on a website if they were explicitly disallowed from accessing the whole website or were part of a wildcard that disallowed access to the whole website OR if the content they were allowed to crawl was extremely minimal and of little importance.
If a bot was blocked from crawling the same content a search engine or news engine was blocked from, as long as it wasn’t the entire website, then this was considered a normal usage and is not notated below.
If a bot was blocked from crawling content, but not in the same way a search engine or news engine bot was allowed to crawl, then it was labeled as being blocked from crawling some content on the site instead of all content.
You can use this information to better understand your link reports from tool providers and to help understand why agencies and SEO consultants like myself typically recommend using more than one link analysis tool to understand a backlink profile.
Ahrefs
Bot name: Ahrefsbot
Blocked from: 19/215
Blocked from crawling all content on
- Netflix
- Yelp
- Daily Mail
- Google News
- Github
- Nextdoor
- Newsmax.com
- Washington Times
- Gothamist
- West Word
- Phoenix New Times
- Miami New Times
- Houston Press
- Dallas Observer
- The Hill
Blocked from crawling some content on
- USA Today
Majestic
Bot name: MJ12bot
Blocked from: 16/215
Blocked from crawling all content on
- Wikipedia
- Netflix
- Yelp
- Google news
- Github
- Nextdoor
- Gothamist
- West Word
- Phoenix New Times
- Miami New Times
- Houston Press
- Dallas Observer
Blocked from crawling some content on
- USA Today
Moz
Bot name: Rogerbot
Blocked from: 9/215
Blocked from crawling all content on
- Netflix
- Yelp
- Google News
- Nextdoor
- Gothamist
Blocked from crawling some content on
- USA Today
- New York Daily News
SEMRush
Bot name: Semrushbot
Blocked from: 10/215
Blocked from crawling all content on
- Netflix
- Yelp
- Google News
- Github
- Nextdoor
- Gothamist
Blocked from crawling some content on
- USA Today
Facebook & Instagram
Facebook and Instagram block all crawlers except those from other search engines and a few social media websites/services. Social Media websites that Facebook and Instagram allow to crawl them are: Twitter [Twitterbot] and Discord [Yeti]. The only other web crawler allowed to index content is Archive.org [ia_archiver].
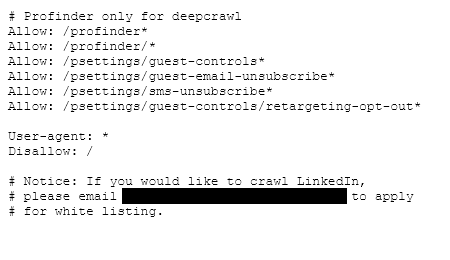
LinkedIn allows 2 of the 4 major link indexes by explicitly allowing them in their robots.txt. To get added to the whitelist LinkedIn includes an email address at the bottom of their robots.txt that services can send a request to be added. That means 2 out of the 4 either haven’t requested this access or have been rejected by LinkedIn.
Wikipedia
Wikipedia has explicitly blocked Majestic [MJ12bot] stating that it was observed ignoring their rate limit request. Majestic is the only link index blocked from crawling Wikipedia. Here is the note about this block from their robots.txt file
Observed spamming large amounts of https://en.wikipedia.org/?curid=NNNNNN
# and ignoring 429 ratelimit responses, claims to respect robots:
Like Wikipedia, Reddit appears to think the MJ12bot from Majestic has misbehaved as it is the only bot out of the 4 examined here blocked from crawling content on Reddit. I used Archive.org to determine this block happened in the summer of 2016 between July 14th and August 15th.
If you are a Majestic user and that is your only way to view links to your website, then you should be able to find at least posts made that link to your content by viewing your domain page. You can find that at Reddit.com/Domains/[Example.com]
Yelp
Yelp, much like other large websites, only allows specific crawlers to visit their site. For the most part these are all search engine and social media bots including Twitter and Telegram but doesn’t allow Facebook’s bot [Facebookexternalhit]. This means pretty much all SEO tools and link indexes are blocked from crawling Yelp so you won’t find Yelp data in your link reports, although oddly they do allow Deep Crawl [DeepCrawl] to access their site.
Google News, Netflix, Nextdoor, and others
Many major services block nearly all bots, including Google’s own Google News which blocks all bots and even largely blocks their own crawler [Googlebot] from accessing specific content. These probably aren’t impacting your view of your websites own inbound links as websites like these either don’t link out or the links probably wouldn’t matter for SEO anyways.
News Websites
I was a little shocked at the level of blocking I found while examining popular news media robots.txt files. While most have standard files that allow all access or block some sensitive areas like an admin URL, several of them had explicitly disallow listings for a few link index bots. Largely these were targeted at Ahrefs [Ahrefsbot] and Majestic [MJ12bot]. One group of publications is owned by a company in Colorado called Voice Media Groupe. They own publications including the Miami New Times, Houston Press, and Dallas Observer. Voice Media doesn’t just own these publications, but they also claim to be an SEO agency, which tells me if they are blocking Majestic and Ahrefs then they likely use Moz, SEMRush or another solution for link analysis.
Conclusion
While all of these tools are great, this shows me that really you can’t trust using just one link analysis tool to understand the impact of your link building campaigns. Robots.txt files are also very easy to update and with the new pending standard are all likely to get overhauled soon, which means these files and how bots from backlink tools like those examined here can crawl will change over time. If you’re serious about tracking your inbound links, then you’ll really want to have at least two of these indexes at your disposal.
I’d recommend something like Ahrefs/Majestic + Moz/SEMRush for maximum effectiveness.
If you want to crawl sites like Facebook, Instagram, Yelp, and Nextdoor to understand links from those websites to yours, then you’ll have to find another solution as any SEO tool or link index is unlikely to be able to display this data.
Top 100 Websites Without a Robots.txt
For fun while I was digging through the robots.txt files on SimilarWeb’s Top 100 USA website list I found two without any robots.txt files. I found it interesting that websites with large volumes of traffic like these wouldn’t have one of the more basic technical components of a website.
- Drudge Report
- Weather.gov